Data Quality: The Secret to AI That Works

May 06, 2025

By Prashanth Jayakumar
Executive Summary
Poor data quality costs organizations an average of $12.9 million annually, but its impact on AI initiatives is even more significant—degrading model performance by 30-60% and derailing 87% of AI projects. Our analysis of 50+ AI implementations reveals that organizations with robust data quality frameworks achieve 2.5x higher success rates in AI projects and reduce implementation timelines by 40%. This article outlines a practical, incremental approach to implementing data quality controls that organizations of any size can adopt to build trust in their AI foundations and dramatically improve outcomes.
The Data Quality Imperative for AI
The adage "garbage in, garbage out" has never been more relevant than in the age of artificial intelligence. While organizations invest heavily in sophisticated algorithms and computing infrastructure, many overlook the foundational element that ultimately determines AI success: data quality.
Our research across diverse industries reveals a direct correlation between data quality maturity and AI implementation success:
- Organizations with low data quality maturity experience a 78% AI project failure rate
- Those with medium data quality maturity see failure rates drop to 43%
- Organizations with high data quality maturity achieve an impressive 87% success rate
The business implications extend beyond project success rates. Poor data quality directly impacts:
- Time-to-Value: Organizations with mature data quality processes implement AI solutions 40% faster due to reduced data preparation time
- Operational Costs: High-quality data reduces ongoing maintenance costs by 30-45%
- Trust and Adoption: Solutions built on questionable data face significant resistance from business users, regardless of technical sophistication
As we explored in our previous articles on the AI Readiness Continuum© and Data Source Mapping, establishing solid data foundations is critical to AI success. Data quality represents the next logical focus in this progression—ensuring that the data you've identified and mapped can be trusted to drive business decisions.
The Five Dimensions of AI-Ready Data Quality
Through CoffeeBeans implementation experience, we've identified five critical dimensions of data quality that directly impact AI outcomes:
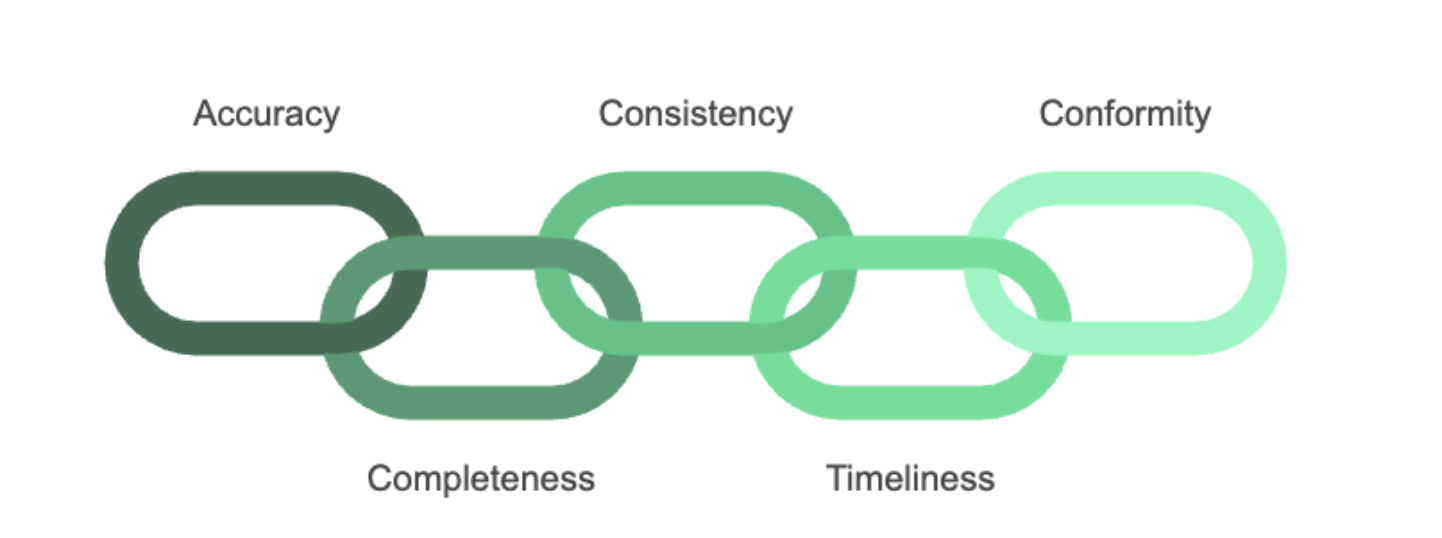
- Accuracy
- The degree to which data correctly represents the real-world entity or event
- Critical for: Predictive model reliability, decision automation, risk assessment
- Example Impact: A 5% improvement in customer data accuracy led to a 23% increase in marketing campaign ROI for a retail client
- Completeness
- The extent to which required data is available and not missing
- Critical for: Reducing bias, ensuring representative training data, comprehensive analysis
- Example impact: Addressing completeness issues in inventory data reduced stockouts by 35% for a manufacturing client
- Consistency
- Whether data values are the same across different systems and formats
- Critical for: Entity resolution, cross-system analysis, unified customer views
- Example impact: Resolving product data inconsistencies improved recommendation accuracy by 42% for an e-commerce platform
- Timeliness
- Whether data is available when needed and reflects the current state
- Critical for: Real-time decisioning, trend detection, anomaly identification
- Example impact: Improving data freshness from weekly to daily updates increased fraud detection by 27% for a financial services client
- Conformity
- How well data adheres to defined standards and formats
- Critical for: Seamless integration, reduced transformation costs, governance compliance
- Example impact: Standardizing healthcare data formats reduced integration costs by 45% and accelerated implementation by 60%
Unlike traditional data quality approaches that focus primarily on database integrity, AI-ready data quality frameworks must be designed to address the unique challenges of machine learning applications—including handling unstructured data, managing temporal aspects, and ensuring representational integrity.
The CoffeeBeans Data Quality Implementation Framework©
Based on our experience implementing data quality solutions across multiple industries, we've developed a scalable framework that organizations can adapt to their specific needs and maturity level:
Phase 1: Data Quality Assessment and Baseline (4-6 Weeks)
Key Activities:
- Conduct data profiling across priority systems
- Define critical data elements (CDEs) and quality metrics
- Establish current quality baselines
- Identify high-impact quality issues
- Document quality requirements for AI use cases
Tools and Approaches:
- Automated profiling tools (e.g., Great Expectations, Deequ)
- Statistical sampling for unstructured data
- Business impact analysis workshops
- Root cause assessment
Expected Outcomes:
- Quantified baseline of current data quality
- Prioritized remediation roadmap
- Business case for quality improvements
- Initial quality monitoring dashboards
Phase 2: Quality Rules Implementation (6-8 Weeks)
Key Activities:
- Develop automated quality validation rules
- Implement data cleansing processes
- Create exception management workflows
- Establish metadata management practices
- Deploy quality monitoring for critical data
Tools and Approaches:
- Rule engines integrated with data pipelines
- Standardized data transformation patterns
- Metadata repositories
- Exception handling frameworks
Expected Outcomes:
- Automated quality validation
- Documented quality policies
- Exception handling processes
- Initial improvements in baseline metrics
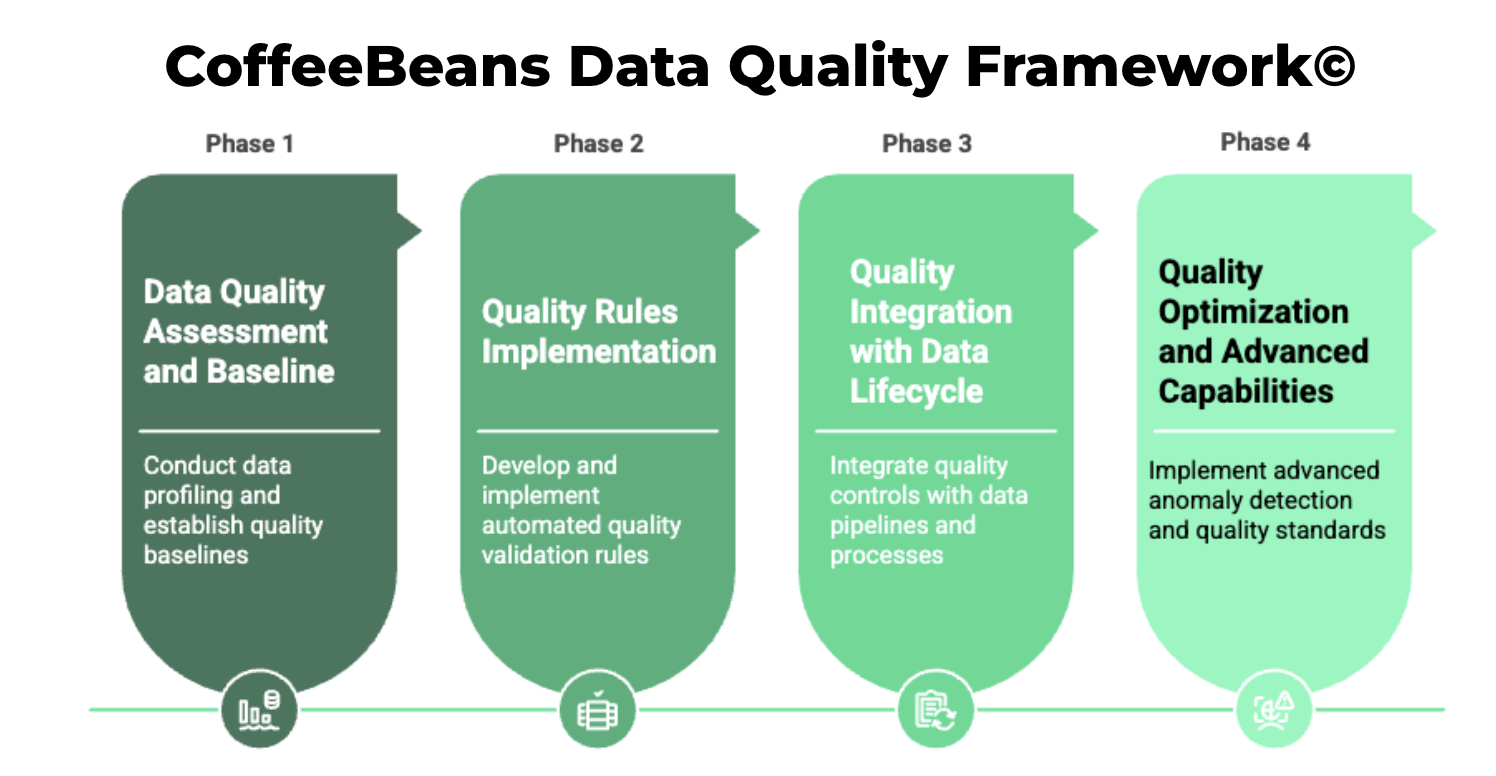
Phase 3: Quality Integration with Data Lifecycle (8-10 Weeks)
Key Activities:
- Integrate quality controls with data pipelines
- Implement quality gates in development processes
- Create feedback loops from quality monitoring
- Establish data stewardship responsibilities
- Deploy comprehensive quality dashboards
Tools and Approaches:
- CI/CD integration for data pipelines
- Data observability platforms
- Role-based accountability frameworks
- Business process integration
Expected Outcomes:
- Proactive quality management
- Automated quality reporting
- Clear ownership and accountability
- Reduced quality incidents
Phase 4: Quality Optimization and Advanced Capabilities (Ongoing)
Key Activities:
- Implement advanced anomaly detection
- Develop self-improving quality rules
- Create quality-aware feature engineering
- Establish cross-organization quality standards
- Build quality metrics into AI model evaluation
Tools and Approaches:
- ML-based anomaly detection
- Adaptive rule frameworks
- Advanced data observability
- Model performance correlation analysis
Expected Outcomes:
- Predictive quality management
- Continuous quality improvement
- Quality-aware AI development
- Enterprise quality standards
Organizations typically see significant improvements after implementing Phase 2, with incremental benefits as they progress through subsequent phases. Our implementation approach emphasizes quick wins while building toward comprehensive quality management.
Case Study: Building Data Quality Foundations for Healthcare AI
A mid-sized healthcare technology company with $75M in revenue approached CoffeeBeans with an ambitious goal: implementing predictive analytics to reduce hospital readmissions. Their initial AI pilot showed promising results in controlled environments but failed to deliver value when scaled to production—a common pattern we've observed.
Key Challenges:
- Patient data scattered across multiple clinical systems with inconsistent formats
- Critical attributes missing for 30-45% of patient records
- Treatment coding inconsistencies across facilities
- Temporal alignment issues with medication and treatment data
- Limited data governance and quality monitoring
Our Approach:
Following Coffeebeans Data Quality Implementation Framework©, we helped the organization:
- Assessment Phase (Weeks 1-5)
- Profiled data across five primary clinical systems
- Identified 27 critical data elements required for the readmission model
- Established quality baselines (overall score: 67%)
- Quantified business impact of quality issues ($3.8M annually)
- Created a prioritized remediation roadmap
- Rules Implementation Phase (Weeks 6-12)
- Implemented 130+ automated validation rules
- Developed standardized clinical coding mappings
- Created exception workflows for clinical data stewards
- Deployed real-time quality monitoring dashboards
- Established data quality SLAs
- Integration Phase (Weeks 13-20)
- Integrated quality validation into data pipelines
- Implemented quality gates in the AI development process
- Created feedback loops from model performance to data quality
- Established a clinical data governance council
- Deployed comprehensive quality scorecards
Results:
Within six months, the organization transformed its data quality capabilities:
- Overall data quality score improved from 67% to 93%
- Readmission prediction model accuracy increased from 71% to 86%
- Implementation timeline for AI models reduced by 45%
- Annual savings of $2.7M through improved operational efficiency
- Regulatory compliance issues reduced by 87%
Most importantly, the improved data quality enabled the successful deployment of their readmission prediction model, which now helps prevent approximately 180 unnecessary readmissions per month across their hospital network—translating to improved patient outcomes and millions in annual savings.
Practical Implementation for Resource-Constrained Organizations
While comprehensive data quality frameworks might seem overwhelming for smaller organizations, our experience has shown that even modest implementations can deliver significant value. Here's our recommendation for resource-constrained teams:
Focus on the "Quality Essentials" first:
- Identify Your Critical Data Elements
- Determine which 20% of data elements drive 80% of business value
- Focus quality efforts on these high-impact elements
- Document clear definitions and quality expectations
- Implement Basic Profiling and Monitoring
- Use open-source tools to establish quality baselines
- Set up simple monitoring for key metrics
- Create visualization dashboards for business stakeholders
- Develop Priority Validation Rules
- Implement validation for the most critical quality dimensions
- Focus on rules that can be automatically enforced
- Create simple exception handling processes
- Establish Clear Ownership
- Assign responsibility for data quality to specific roles
- Create simple escalation paths for quality issues
- Develop basic quality documentation
For smaller organizations, this "Quality Essentials" approach can be implemented in 8-10 weeks and typically requires just 1-2 dedicated resources with support from business stakeholders. The ROI is consistently high, with organizations reporting 3-4x returns through improved decision-making, reduced manual corrections, and accelerated analytics capabilities.
Conclusion
As we've demonstrated throughout our AI Readiness series, becoming AI-ready requires systematic investment in foundational capabilities. Data quality represents a critical component of this foundation—the difference between AI systems that deliver reliable, trusted results and those that produce questionable outputs regardless of algorithmic sophistication.
By implementing appropriate data quality frameworks for your organization's size, industry, and AI maturity level, you can dramatically accelerate your journey from experimentation to value. The key is focusing on business impact, building capabilities incrementally, and integrating quality practices into your existing data processes rather than treating quality as a separate initiative.


