Fine-Tuning Retrieval-Augmented Generation (RAG) for Domain-Specific Large Language Models

December 05, 2024

Introduction
In recent years, Large Language Models (LLMs) like GPT, BERT, and their derivatives have transformed the AI landscape by enabling powerful applications in natural language processing (NLP). However, these models often face challenges in generating accurate, relevant, and domain-specific responses, particularly when dealing with niche knowledge areas. Retrieval-Augmented Generation (RAG) emerges as a robust solution to this limitation by combining the generative capabilities of LLMs with a retrieval system that fetches relevant, context-specific information.
This blog delves into fine-tuning RAG for domain-specific applications, exploring the architecture, implementation, best practices, and potential future developments.

Understanding Retrieval-Augmented Generation (RAG)
What is RAG?
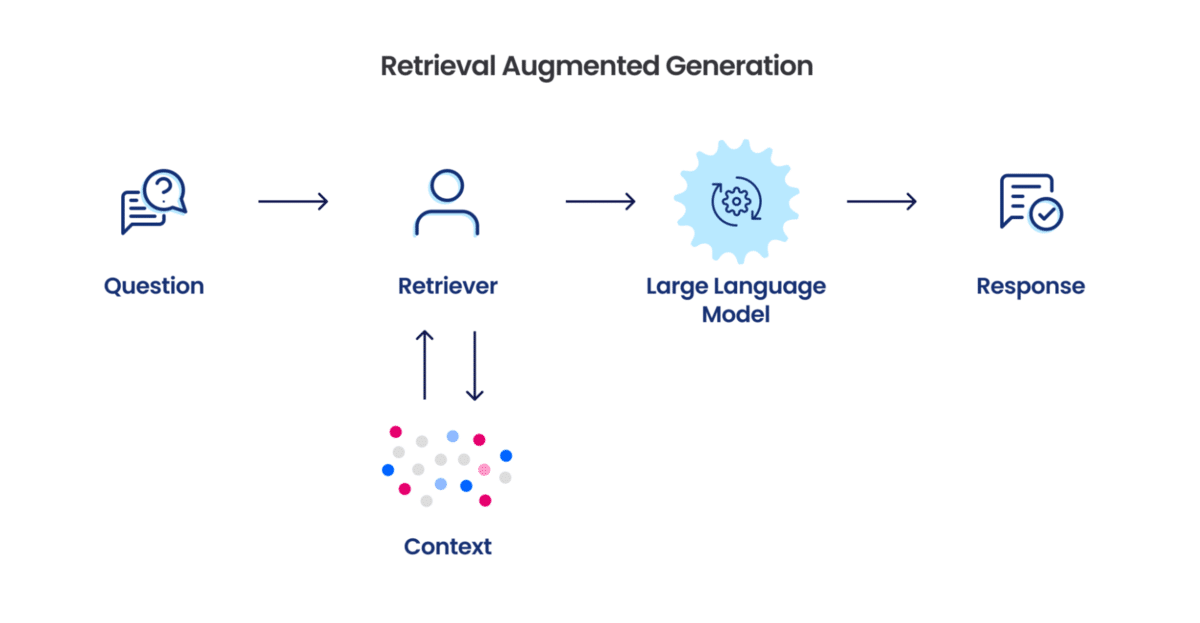
RAG is a hybrid model architecture that combines:
- Retriever: A system that searches and retrieves relevant documents or knowledge snippets from a database, knowledge graph, or API.
- Generator: A language model that uses the retrieved information to generate responses, ensuring relevance and factual accuracy.
This synergy allows RAG models to leverage external knowledge bases, improving response precision and reducing the risk of hallucinations.
Why Fine-Tune RAG for Domain-Specific Applications?
Fine-tuning a RAG model for domain-specific use cases enhances its ability to:
- Address Highly Specialized Queries
RAG fine-tuning enables precise responses to niche or technical questions by incorporating domain-specific knowledge directly into the retrieval and generation pipeline. This ensures the model caters to industry-specific jargon and unique problem statements.
- Generate More Context-Aware, Accurate, and Actionable Insights
By leveraging relevant external knowledge, RAG models enhance the contextual understanding of queries, improving the quality and applicability of the generated outputs. This makes the insights actionable and reliable for decision-making in specialized fields.
- Integrate Proprietary or Confidential Knowledge Bases
Fine-tuned RAG models can incorporate secure and private datasets, ensuring compliance with data governance while generating responses. This allows organizations to utilize sensitive information without exposing it to external systems.
- Reduce Dependency on Generic, Pre-Trained Knowledge
Generic LLMs may lack depth in specific areas, but fine-tuning RAG reduces this reliance by enriching responses with targeted data sources. This customization ensures the model is aligned with organizational goals and domain expertise.
Examples of domain-specific applications include:
- Healthcare: Assisting doctors with diagnosis by referring to medical literature.
- Legal: Providing case-law references for legal professionals.
- Finance: Answering questions about market trends using proprietary reports.
- Education: Offering tailored academic content and explanations.
Core Architecture of RAG
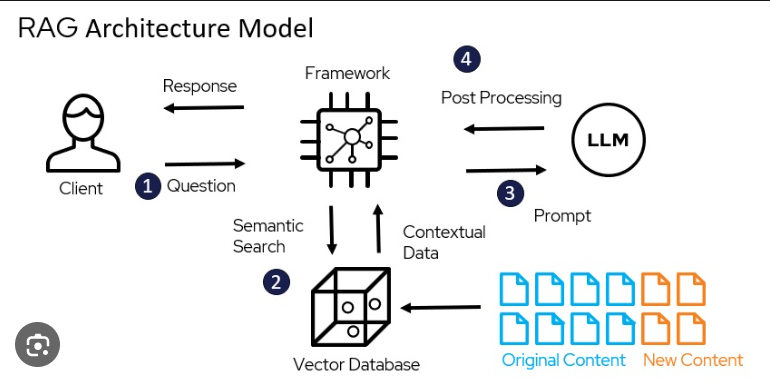
1. Retriever
The retriever locates relevant documents based on the input query. Common approaches include:
- Sparse Retrieval: Techniques like TF-IDF or BM25 that rely on keyword matching.
- Dense Retrieval: Leveraging neural networks, such as Sentence-BERT, to encode queries and documents into dense vector spaces for similarity searches.
2. Generator
The generator, typically an LLM, uses the query and retrieved context to produce the final output. Examples include:
- OpenAI’s GPT Family
The GPT series, including models like GPT-4, are highly versatile and widely used for text generation. These models excel in natural language understanding and generation tasks, making them a popular choice for building RAG systems due to their pre-trained capabilities on vast datasets.
- Google’s T5 (Text-to-Text Transfer Transformer)
T5 converts all NLP tasks into a text-to-text format, enabling consistent processing for various applications like translation, summarization, and classification. Its flexibility and efficiency make it a strong candidate for RAG systems requiring domain-specific text processing.
- Meta’s LLaMA (Large Language Model Meta AI)
LLaMA focuses on delivering high performance with smaller, more efficient models, making it suitable for specialized deployments. It offers competitive results in text generation and understanding tasks, making it a cost-effective option for domain-specific RAG implementations.
3. Knowledge Base
The retriever queries a structured or unstructured knowledge base, which could be:
- Document Store (e.g., Elasticsearch)
A document store organizes data in a searchable format, often optimized for text-based queries. Elasticsearch, a widely used solution, allows efficient full-text searches across structured and unstructured documents, making it ideal for RAG systems that rely on keyword-based retrieval.
- Vector Database (e.g., Pinecone, FAISS)
Vector databases store data as dense embeddings, enabling similarity searches based on contextual relevance rather than exact matches. Pinecone and FAISS are popular choices, offering fast and scalable vector retrieval, crucial for dense retrieval in RAG models.
- API or External Knowledge Graph
APIs and knowledge graphs provide structured, dynamic data that can enrich retrieval with interconnected concepts. External knowledge sources, like Wikidata or proprietary APIs, allow RAG systems to fetch real-time, domain-specific, or highly relational information for accurate responses.
4. Fusion of Multiple Retrieved Sources in RAG
RAG’s fusion mechanism aggregates information from various retrieved documents or data points, ensuring that all relevant contexts are considered. This process synthesizes insights, resolves conflicts, and eliminates redundancies to provide a cohesive, contextually rich, and accurate response tailored to the input query.
Steps to Fine-Tune a RAG Model
Fine-tuning RAG involves customizing both the retriever and generator to align with domain-specific needs. Below are the key steps:
1. Preparing the Dataset
Collect Domain-Specific Documents, FAQs, Manuals, or Other ResourcesGathering relevant and high-quality domain-specific data is crucial for training a RAG model. These sources can include technical manuals, industry reports, frequently asked questions (FAQs), academic papers, and proprietary documents, which serve as the knowledge base from which the retriever fetches information.
Preprocess the Data
Effective data preprocessing ensures that the collected documents are in a format suitable for both retrieval and generation tasks:
- Tokenize and Clean Text: Tokenization breaks down the text into smaller units (words or subwords), while cleaning removes noise like special characters, irrelevant symbols, or extra spaces.
- Extract Relevant Entities or Concepts: Named entity recognition (NER) and concept extraction techniques help identify important domain-specific terms (e.g., medical conditions, legal terms) that enhance the retriever’s ability to fetch precise, context-relevant information.
Organize into Retriever-Friendly Formats
To ensure efficient retrieval, the processed data must be transformed into formats that optimize the retrieval process:
- Embeddings: Convert documents into vector representations using models like BERT or Sentence-BERT, making them searchable in dense vector databases.
- Indexed Structures: For sparse retrieval, organize the data into inverted indexes, where keywords and their document associations allow for efficient search and ranking based on relevance.
2. Fine-Tuning the Retriever
Fine-tuning the retriever ensures that the retrieval system is optimized for domain-specific queries, improving relevance and accuracy. This can be done using sparse and dense retrieval techniques.
Sparse Retriever Fine-Tuning
- Optimize Ranking Algorithms (e.g., BM25 parameters): Fine-tune parameters like k1 and b in BM25 to adjust how document relevance is ranked based on term frequency and document length, improving the retrieval of relevant documents in a domain-specific context.
- Implement Domain-Specific Tokenizers or Stop-Word Lists: Customize tokenizers to handle domain-specific terms and abbreviations, while adjusting stop-word lists to filter out irrelevant words, improving the retriever’s accuracy in specialized areas.
Dense Retriever Fine-Tuning
- Train Sentence Transformers Using Contrastive Learning: Train models like Sentence-BERTwith contrastive learning to distinguish between relevant and irrelevant document pairs, ensuring better semantic relevance for domain-specific queries.
- Fine-Tune Pre-Trained Models (e.g., MiniLM, Sentence-BERT): Fine-tune pre-trained models on domain-specific query-document pairs, allowing them to better capture the nuances and vocabulary of the field, improving retrieval precision.
Fine-tuning both approaches enhances the retriever's ability to provide accurate and context-aware results in domain-specific applications.
3. Fine-Tuning the Generator
- Supervised Fine-Tuning with Domain-Specific QA Pairs
Fine-tuning with domain-specific question-answer pairs enables the model to learn the context and specificities of a particular field, improving its ability to generate accurate, relevant answers tailored to that domain.
- Reinforcement Learning for Prioritizing Factual Correctness
Reinforcement learning (RL) techniques can enhance the model by rewarding accurate, domain-relevant responses, guiding the model to prioritize factual correctness and relevance in the answers it generates.
- Efficient Fine-Tuning with LoRA and PEFT
Techniques like LoRA (Low-Rank Adaptation) and PEFT (Parameter-Efficient Fine-Tuning) allow large models to be fine-tuned with limited computational resources by focusing on a small set of parameters, making domain adaptation more resource-efficient.
4. Integrating the Knowledge Base
- Index the domain-specific dataset into a retrievable format:
- Use vector stores like Pinecone for dense embeddings.
- Implement traditional inverted indices for sparse retrieval.
- Ensure the knowledge base is regularly updated.
5. Evaluating Performance
Key evaluation metrics include:
- Precision@K: How relevant the top K retrieved documents are.
- BLEU/ROUGE Scores: For assessing the quality of generated text.
- Domain-Specific Metrics: Accuracy in specific contexts (e.g., clinical accuracy for healthcare models).
Challenges and Solutions
1. Limited Domain Data
- Solution: Use data augmentation techniques such as paraphrasing or synthesizing queries.
2. Model Complexity
- Solution: Use lightweight fine-tuning approaches like LoRA to minimize resource demands.
3. Keeping the Knowledge Base Updated
- Solution: Automate the ingestion and indexing process for new documents.
4. Handling Ambiguity or Low-Quality Data
- Solution: Implement confidence thresholds and fallback mechanisms to gracefully handle ambiguous queries.
Best Practices for Fine-Tuning RAG
- Start Small: Begin with a limited dataset and scale gradually to avoid overfitting.
- Leverage Pre-Trained Models: Use pre-trained retrievers and generators as a foundation.
- Iterative Optimization: Fine-tune in cycles, alternating between retriever and generator for incremental improvement.
- User Feedback Loops: Incorporate end-user feedback to refine model responses.
Applications of Fine-Tuned RAG
- Healthcare
Assist in diagnosis and treatment planning using up-to-date medical literature.
- Legal
Generate case summaries or legal advice based on jurisprudence.
- Customer Support
Enhance chatbots with domain-specific FAQs and troubleshooting guides.
- Education
Provide detailed explanations for academic queries, personalized to a student's curriculum.
- Enterprise Knowledge Management
Answer employee questions by leveraging internal documentation.
Future Scope of RAG in Domain-Specific Applications
1. Contextual Awareness
Future RAG models will enhance their contextual understanding by integrating multi-modal inputs (e.g., text, images, audio). This will enable them to generate richer, more nuanced responses that consider diverse forms of data for a deeper comprehension of queries.
2. Real-Time Updates
With automated pipelines for real-time knowledge base indexing, RAG models will ensure they always access and provide the most up-to-date information, making them more reliable and relevant for dynamic, fast-changing fields.
3. Explainability
Improving the transparency of both the retrieval and generation processes will increase trust in RAG systems, particularly in high-stakes domains such as healthcare and law, where understanding how decisions are made is crucial for accountability and compliance.
4. Scalability
Future RAG models will be optimized for low-resource environments, including edge devices and on-premise deployments, making them more accessible and practical for a wider range of applications without relying on high-powered infrastructure.
5. Specialized Architectures
Domain-specific RAG models will emerge, tailored to industries such as healthcare (e.g., HIPAA-compliant models) or finance, enabling more precise and context-aware responses while adhering to industry regulations and requirements.
Conclusion
Fine-tuning RAG for domain-specific applications represents a transformative step in applying LLMs to real-world problems. By combining the retrieval power of dense or sparse methods with the generative capabilities of LLMs, RAG systems can bridge the gap between generic AI and highly specialized knowledge.
The road ahead is promising, with opportunities to refine models for better accuracy, explainability, and adaptability. Organizations looking to adopt RAG should invest in high-quality data curation, iterative fine-tuning processes, and robust evaluation frameworks to maximize the potential of this cutting-edge technology.


