A reframing tech infrastructure with an 81% increase in green deployment with advanced tech interventions
Client wanted to manage the product release process and post productionsupport.They also looked for assistance in management of the infrastructure team to ensure that deployment protocols are followed and the pipelineruns smoothly.

Challenges
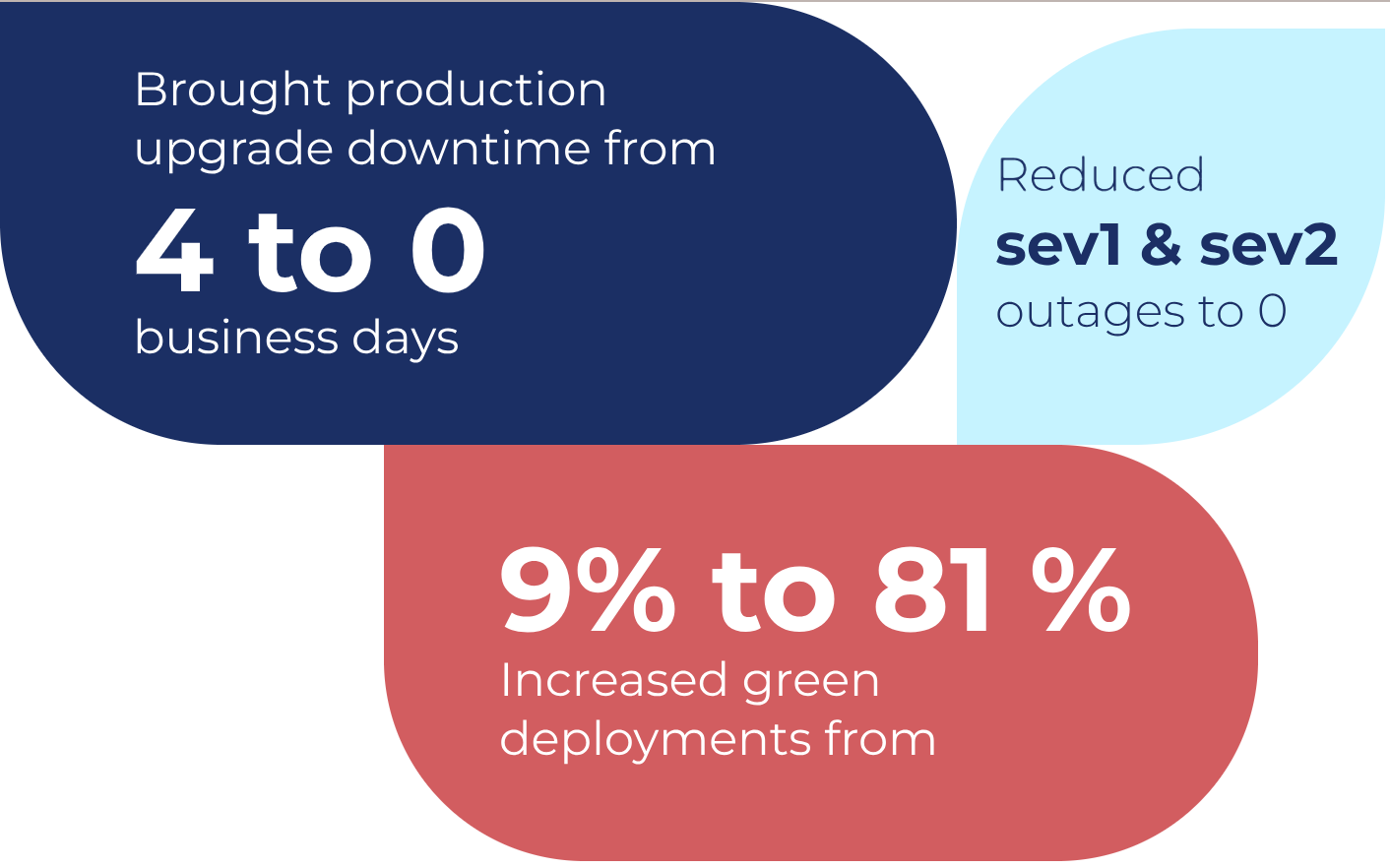
When scheduled, each production upgrade resulted in a 300% increase in system downtimes, flaky systems after the upgrade, internal teams becoming burnt out, reducing productivity, and longer cycles between releases, reducing market penetration. Overall, the impact on business revenue and the end customer's trust in our client
Prolonged deployment downtimes during production upgrades
It was not a rolling deployment due to the technology stack. This resulted in definite downtimes for a production upgrade. The end customer was promised a one-day downtime. Due to unanticipated issues, it would eventually result in a 3/4 day downtime.
Flaky production upgades
Most production upgrades resulted in the app not working immediately after the upgrade, resulting in additional downtime and revenue loss. Following a production upgrade, multiple sev 1 and sev 2s were logged
Prioritsation of post-production issues
Production issues were logged from multiple locations due to multiple end customers. While the team was technically proficient, there was a significant gap in prioritizing these incoming requests while keeping the business impact, available bandwidth, and so on in mind. As a result, the team worked long hours and burned out faster.
Solution
Production issues were logged from multiple locations due to multiple end customers. While the team was technically proficient, there was a significant gap in prioritizing these incoming requests while keeping the business impact, available bandwidth, and so on in mind. As a result, the team worked long hours and burned out faster.
- Prolonged deployment downtimes during production upgrades: We found problems in production upgrades in three releases. Gave solutions of top four recurring patterns. We ensured that situation changed, such as developing internal checklist, quality checks, solving dependency upgrades, introducing processes such as deployment windows, pre-approvals, and shielding upgrade team.
- Flaky production upgades: Some approaches we took for this included defining the Definition of Done at each stage prior to deployment upgrade, sharing ownership for production upgrade across all teams rather than just the upgrade team, and introducing checklists and quality gate processes.
- Prioritsation of post-production issues: Production issues were routed through a review tunnel for prioritization, considering factors like available bandwidth & impact. Clear expectations for SLAs of production issues and POCs were achieved. This aided production support team in efficiency, and achieving a stage with no incidents in active lane.
Implementation & Results
The combined impact of all of the changes mentioned above, as well as some others, resulted in a visible improvement in end-customer trust in the client, and thus the client's trust in us, thus improving client relationships. Production upgrades were also much smoother, allowing the rest of the team to shift their focus away from firefighting and toward more revenue-generating features.
Quarterly Goals